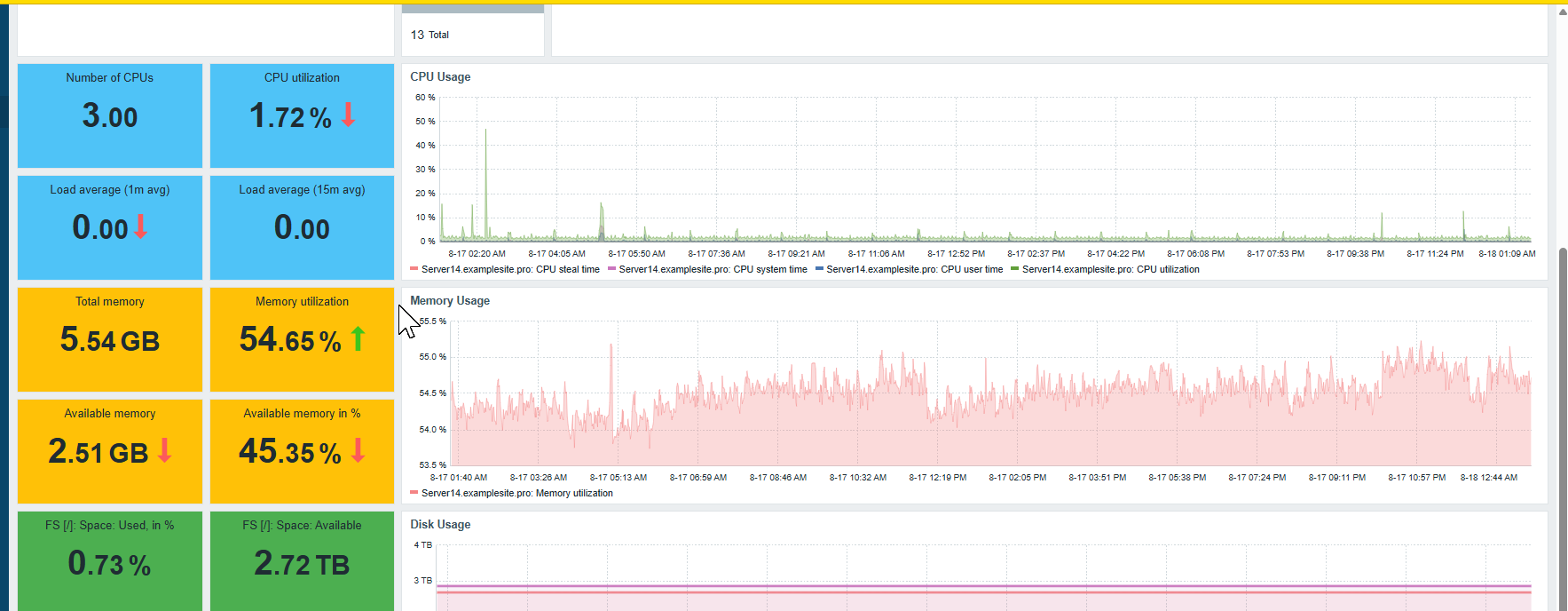
In the world of modern infrastructure, things rarely “break all at once.” Systems degrade slowly—CPU usage creeps up, disk space dwindles, load spikes become more frequent, queries start running slower, SSL certificates inch toward expiration. Every outage has a trail of warning signs leading up to it.
That’s why continuous monitoring is one of the most important parts of maintaining the health, stability, and security of your servers and websites. Good monitoring doesn’t just alert you when something is down—it gives you the visibility to prevent downtime in the first place.
Early Detection = Faster Fixes = Happier Users
Most system failures don’t come out of nowhere. They develop gradually:
- A service begins restarting occasionally
- A database query slows down
- A filesystem fills up
- A certificate approaches expiration
- A site starts timing out under load
With proper monitoring in place, these red flags show up long before they affect end users.
For example:
Without monitoring:
Your site suddenly goes offline because the disk hit 100% full.
With monitoring:
You received warnings at 80%, 90%, and 95%, giving you time to investigate, clean up, or expand storage before any outage occurred.
This small difference determines whether your users never notice a problem—or whether everything grinds to a halt.
A system isn’t healthy just because it’s online. True health comes from consistency, predictability, and performance stability.
Monitoring gives you insights like:
- CPU patterns during peak hours
- Memory usage trends over days or weeks
- Database performance changes after updates
- Network throughput under varying traffic loads
- Error rate spikes in application logs
This historical data is invaluable:
- You can spot degradation early.
- You can size resources correctly.
- You can identify bottlenecks before users complain.
- You can plan scaling based on real usage, not guesswork.
Simply put, you can’t improve what you can’t see.
Proactive Alerts Prevent Emergencies
Systems should never catch you off guard. Alerts for key issues ensure you stay ahead of trouble:
Critical alerts
- Service down
- Server unreachable
- Database crash
- SSL certificate expired
Warning alerts
- High CPU or load average
- Rising memory consumption
- Disk space trending toward full
- Latency spikes
- Slow query detection
- DNS or email failures
Warnings are early warnings. They exist to stop critical issues from ever happening.
Monitoring flips the model from reactive firefighting to proactive maintenance, which is where stable infrastructure comes from.
It Reduces Downtime and Protects Revenue
Every minute a system is down:
- Visitors leave
- Sales stop
- Support tickets spike
- Reputation suffers
Monitoring doesn’t just protect servers—it protects the business.
When you can fix issues before they cause outages, downtime becomes rare instead of inevitable.
Monitoring Also Improves Security
Not all threats are sudden hacks; many security breaches start with subtle anomalies:
- Unexpected new processes
- Unusual outbound connections
- Login attempts from unknown sources
- Sudden CPU/network spikes
- Unexpected configuration changes
Monitoring tools alert you to suspicious activity long before damage is done.
Security isn’t just about firewalls—it’s about visibility.
Monitoring Isn’t Optional — It’s a Requirement for Modern Infrastructure
Whether you manage a single VPS or a full cluster, monitoring is one of the most effective ways to ensure stability, performance, and user satisfaction.
It lets you:
- Detect issues early
- Prevent outages
- Understand performance trends
- Plan capacity intelligently
- Improve security
- Provide a better user experience
- Reduce stress and emergency fixes
Simply put: Monitoring is cheaper, easier, and far more effective than recovering from downtime.